告警通知
企业管理员在企业管理-监控与告警-告警通知中查看系统一段时间内的活跃告警, 如下图所示:
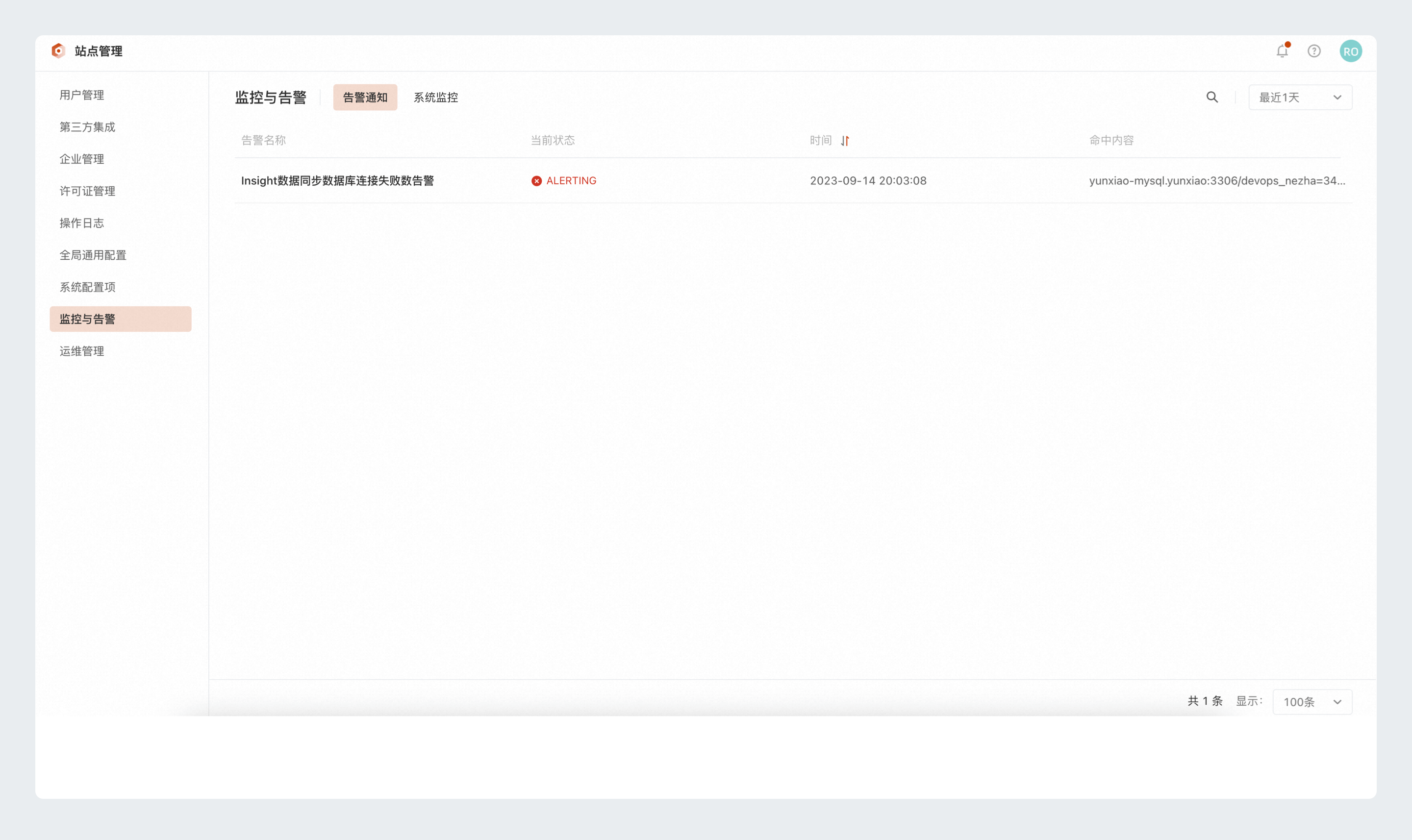
每条告警记录包含:
- 告警名称:告警的内容,点击可跳转到该项告警对应的监控图表。
- 当前状态:当前告警的状态,告警包含五个状态:Normal、Pending、Alerting、NoData、Error,重点关注处于Alerting状态的告警。
- 时间:告警产生的时间。
- 命中内容:与该条告警相关的资源,常为解决该告警问题需要处理的资源对象。
核心业务指标告警说明及处理方法
Yunxiao-Pod5min内重启次数大于等于 3
所属产品:通用
问题分析:检查Pod负载和日志,做进一步分析,如果长期负载过高,考虑登录运维POD升配
Yunxiao-容器CPU使用率大于80%
所属产品:通用
问题分析:检查Pod负载和日志,做进一步分析,如果长期负载过高,考虑登录运维POD重启或升配
Yunxiao-容器内存使用率大于85%
所属产品:通用
问题分析:检查Pod负载和日志,做进一步分析,如果长期负载过高,考虑登录运维POD重启或升配
Yunxiao-节点CPU使用率超过80%
所属产品:通用
问题分析:查看各节点的负载和该节点上 POD 的 CPU 使用率,尝试登录运维POD重启高 CPU 使用率的 POD
Yunxiao-节点状态异常
所属产品:通用
问题分析:查看节点连通性,如果连通性有问题,查看是否负载过高
Yunxiao-节点磁盘可用率不足20%
所属产品:通用
问题分析:尝试对节点磁盘进行扩容或登录节点清理
中间件ETCD服务出现异常
所属产品:通用
问题分析:最近1分钟ETCD服务出现异常,请检查ETCD服务是否正常运行,如有异常请尝试重启该服务。
Appstack工单状态推送成功率低于60%告警
所属产品:appstack
问题分析:检查appstack命名空间下biz、change-controller、ade2-deploy-scheduler状态是否均为Running,若有否频繁重启可以适当pod调高内存。登录运维POD后重启 biz, 命令如下:
kubectl -n appstack rollout restart deployment appstack-biz
Appstack应用操作成功率低于90%告警
所属产品:appstack
问题分析:检查appstack命名空间下biz、core状态是否均为Running,若有否频繁重启可以适当pod调高内存。登录运维POD后重启 biz, 命令如下:
kubectl -n appstack rollout restart deployment appstack-biz
Appstack应用环境操作成功率低于90%告警
所属产品:appstack
问题分析:检查appstack命名空间下biz、core状态是否均为Running,若有否频繁重启可以适当pod调高内存。登录运维POD后重启 biz, 命令如下:
kubectl -n appstack rollout restart deployment appstack-biz
Appstack应用编排操作成功率低于90%告警
所属产品:appstack
问题分析:检查appstack命名空间下biz、core状态是否均为Running,若有否频繁重启可以适当pod调高内存。登录运维POD后重启 biz, 命令如下:
kubectl -n appstack rollout restart deployment appstack-biz
Appstack提交部署单成功率低于90%告警
所属产品:appstack
问题分析:检查appstack命名空间下biz、change-controller、core等状态是否均为Running,若有否频繁重启可以适当pod调高内存。登录运维POD后重启 biz, 命令如下:
kubectl -n appstack rollout restart deployment appstack-biz
Appstack部署调度消息成功率低于90%告警
所属产品:appstack
问题分析:1、检查appstack命名空间下ade2-deploy-scheduler状态是否均为Running;2、检查appstack命名空间下appstack-rocketmq服务是否正常,可以重启服务。登录运维POD后重启 rocketmq, 命令如下:
kubectl -n appstack rollout restart statefulsets appstack-rocketmq-namesrv
Codeup产品命令行成功率过低告警
所属产品:codeup
问题分析:
- 检查Node磁盘。进入「企业管理」-「系统监控」-「K8s集群Node磁盘使用水位」,查看Node的磁盘使用率( disk usage )是否接近 100% ,如果接近 100% 请尝试扩容磁盘,或者联系云效技术人员提供支持。
登录运维POD后重启 httpd、sshd、force-dock、satellite 服务, 命令如下:
# 重启 httpd 服务 kubectl rollout restart deployment force-httpd -n codeup # 重启 sshd 服务 kubectl rollout restart deployment force-sshd -n codeup # 重启 force-dock 服务 kubectl rollout restart deployment force-dock -n codeup # 重启 force-dock 服务 kubectl rollout restart deployment force-satellite -n codeup登录运维POD后检查 httpd、sshd 的服务日志是否存在明显异常,命令如下:
# 查看 httpd 服务日志 kubectl logs -f --tail 300 -l app=force-httpd -n codeup # 查看 sshd 服务日志 kubectl logs -f --tail 300 -l app=force-sshd -n codeup
Codeup产品存储服务健康检查异常
所属产品:codeup
问题分析:
- 检查Node磁盘。进入「企业管理」-「系统监控」-「K8s集群Node磁盘使用水位」,查看Node的磁盘使用率( disk usage )是否接近 100% ,如果接近 100% 请尝试扩容磁盘,或者联系云效技术人员提供支持。
登录运维POD后重启 force-core、satellite 服务, 命令如下:
# 重启 force-core 服务 kubectl rollout restart deployment force-core -n codeup # 重启 force-satellite 服务 kubectl rollout restart deployment force-satellite -n codeup
Codeup产品核心接口成功率过低告警
所属产品:codeup
问题分析:
- 检查Node磁盘。进入「企业管理」-「系统监控」-「K8s集群Node磁盘使用水位」,查看Node的磁盘使用率( disk usage )是否接近 100% ,如果接近 100% 请尝试扩容磁盘,或者联系云效技术人员提供支持。
登录运维POD后重启 force-core、satellite 服务, 命令如下:
# 重启 force-core 服务 kubectl rollout restart deployment force-core -n codeup # 重启 force-satellite 服务 kubectl rollout restart deployment force-satellite -n codeup
Insight-postgresql库CPU使用率超过90%告警
所属产品:insight
问题分析:如果长期过高,考虑联系云效技术支持人员进行排查分析后,在低峰期进行扩容或升配
Insight全量任务堆积告警
所属产品:insight
问题分析:检查 data-import 服务的CPU和内存,短期过高,登录运维POD后重启 data-import, 命令如下:
kubectl rollout restart deployment data-import -n yunxiao
;另检查 data-import 的error日志,是否存在连接不上 DB 报错, 如有请检查对应 DB 是否有问题再做进一步排查
Insight增量任务堆积告警
所属产品:insight
问题分析:检查 data-import 服务的CPU和内存,短期过高,可考虑登录运维POD后重启 data-import,命令如下:
kubectl rollout restart deployment data-import -n yunxiao
Insight增量任务延迟告警
所属产品:insight
问题分析:如果是个别任务,则可以观察一段时间,如果仍未恢复,可能是因为某个时点段大批量导入数据导致,如果长期延迟告警,可考虑登录运维POD后重启data-import, 命令如下:
kubectl rollout restart deployment data-import -n yunxiao
Insight报表列表成功率低于80%告警
所属产品:insight
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 metric-collect 的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 metric-collect, 命令如下:
kubectl rollout restart deployment metric-collect -n yunxiao
水平扩容 metric-collect 实例到4台的命令如下:
kubectl scale deployment metric-collect --replicas=4 -n yunxiao
Insight报表详情页面成功率低于80%告警
所属产品:insight
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 metric-collect 的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 metric-collect, 命令如下:
kubectl rollout restart deployment metric-collect -n yunxiao
水平扩容 metric-collect 实例到4台的命令如下:
kubectl scale deployment metric-collect --replicas=4 -n yunxiao
Insight数据同步数据库连接失败数告警
所属产品:insight
问题分析:检查 insight 到 postgresql 的连通性,检查 data-import 服务的CPU和内存,短期过高,尝试登录运维POD后重启 data-import, 命令如下:
kubectl rollout restart deployment data-import -n yunxiao
Packages产品Docker协议成功率低于80%告警
所属产品:packages
问题分析:1. 检查是否有请求熔断,如果长期存在,建议对POD进行扩容;2. 检查存储介质(GlusterFS、OSS)的容量是否已满,权限设置是否正确;3. 检查数据库的连接数和负载
水平扩容 rdc-repository-manage 实例到4台的命令如下:
kubectl scale deployment rdc-repository-manage --replicas=4 -n yunxiao
Packages产品Maven协议成功率低于80%告警
所属产品:packages
问题分析:1. 检查是否有请求熔断,如果长期存在,建议对POD进行扩容;2. 检查存储介质(GlusterFS、OSS)的容量是否已满,权限设置是否正确;3. 检查数据库的连接数和负载
水平扩容 rdc-repository-manage 实例到4台的命令如下:
kubectl scale deployment rdc-repository-manage --replicas=4 -n yunxiao
Packages产品npm协议成功率低于80%告警
所属产品:packages
问题分析:1. 检查是否有请求熔断,如果长期存在,建议对POD进行扩容;2. 检查存储介质(GlusterFS、OSS)的容量是否已满,权限设置是否正确;3. 检查数据库的连接数和负载
水平扩容 rdc-repository-manage 实例到4台的命令如下:
kubectl scale deployment rdc-repository-manage --replicas=4 -n yunxiao
Packages产品上传下载限流率高于20%告警
所属产品:packages
问题分析:检查数据库的连接数和负载,如果连接数和负载正常,且问题长期存在,建议对POD进行扩容
水平扩容 rdc-repository-manage 实例到4台的命令如下:
kubectl scale deployment rdc-repository-manage --replicas=4 -n yunxiao
Packages产品数据库CPU使用率高于90%告警
所属产品:packages
问题分析:如果长期过高,考虑联系云效技术支持人员进行排查分析后,在低峰期进行扩容或升配
Packages产品数据库会话占用率高于80%告警
所属产品:packages
问题分析:如果长期过高,考虑联系云效技术支持人员进行排查分析后,在低峰期进行扩容或升配
Packages产品通用制品协议成功率低于80%告警
所属产品:packages
问题分析:1. 检查是否有请求熔断,如果长期存在,建议对POD进行扩容;2. 检查存储介质(GlusterFS、OSS)的容量是否已满,权限设置是否正确;3. 检查数据库的连接数和负载
水平扩容 rdc-repository-manage 实例到4台的命令如下:
kubectl scale deployment rdc-repository-manage --replicas=4 -n yunxiao
Packages磁盘存储空间使用率高于80%告警
所属产品:packages
问题分析:清理过期制品,或者扩容磁盘
Search容器CPU使用率高于90%告警
所属产品:全搜
问题分析:长期存在,考虑扩容;短期过高,建议尝试 登录运维POD后重启 yunxiao-search, 命令如下:
kubectl rollout restart deployment yunxiao-search -n yunxiao
Search容器内存使用率高于90%告警
所属产品:全搜
问题分析:长期存在,考虑扩容;短期过高,建议尝试 登录运维POD后重启 yunxiao-search, 命令如下:
kubectl rollout restart deployment yunxiao-search -n yunxiao
Search核心搜索接口成功率低于70%告警
所属产品:全搜
问题分析:如果为小范围接口不可用,且有明显500报错,确定复现条件,下载报错日志,反馈云效技术支持同学;检查各POD的负载和磁盘饱和度,按需重启和升配, 登录运维POD后重启 yunxiao-search, 命令如下:
kubectl rollout restart deployment yunxiao-search -n yunxiao
Search连接ES中间件失败数超过5次告警
所属产品:全搜
问题分析:检查 yunxiao-search 与ES的联通性,如果确认是 yunxiao-search 的问题可进行重启, 登录运维POD后重启 yunxiao-search, 命令如下:
kubectl rollout restart deployment yunxiao-search -n yunxiao
如果 yunxiao-search 本身没问题,再检查ES服务状态和负载是否过高,长期过高的话请联系云效技术支持人员进行排查分析后,在低峰期进行ES重启或扩容
Base容器CPU使用率过高报警
所属产品:底座
问题分析:短期过高,尝试重启devops-nezha和devops-spicedb服务;长期过高,建议扩容
登录运维POD后重启 devops-nezha和devops-spicedb, 命令如下:
kubectl rollout restart deployment devops-nezha -n yunxiao
kubectl rollout restart deployment devops-spicedb -n yunxiao
水平扩容 devops-nezha和devops-spicedb 实例到4台的命令如下:
kubectl scale deployment devops-nezha --replicas=4 -n yunxiao
kubectl scale deployment devops-spicedb --replicas=4 -n yunxiao
Base核心业务接口成功率低于96%告警
所属产品:底座
问题分析:尝试重启devops-nezha和devops-spicedb服务;如果仍无法解决问题,请导出日志咨询云效的同学
登录运维POD后重启 devops-nezha和devops-spicedb, 命令如下:
kubectl rollout restart deployment devops-nezha -n yunxiao
kubectl rollout restart deployment devops-spicedb -n yunxiao
Base事件积压率大于20%告警
所属产品:底座
问题分析:尝试重启devops-nezha服务;若无法解决问题,请尝试扩容 yunxiao-redis;如果仍无法解决问题,请导出日志咨询云效的同学
登录运维POD后重启 devops-nezha, 命令如下:
kubectl rollout restart deployment devops-nezha -n yunxiao
水平扩容 yunxiao-redis 实例到2台的命令如下:
kubectl scale statefulsets yunxiao-redis --replicas=2 -n yunxiao
Projex工作项列表成功率低于80%
所属产品: projex
问题分析:查看projex相关的应用,aone-workitem-cloud、aone-common-cloud应用以及projex中间件projex-elasticsearch和projex-mysql的状态,建议尝试重启。
登录运维POD后重启 aone-workitem-cloud, 命令如下:
kubectl rollout restart deployment aone-workitem-cloud -n yunxiao
Projex工作项详情成功率低于80%
所属产品: projex
问题分析:查看projex相关的应用,aone-workitem-cloud、aone-common-cloud应用以及projex中间件projex-elasticsearch和projex-mysql的状态,建议尝试重启。
登录运维POD后重启 aone-common-cloud, 命令如下:
kubectl rollout restart deployment aone-common-cloud -n yunxiao
Projex产品数据库CPU使用率过高报警
所属产品: projex
问题分析:查看projex中间件projex-mysql的状态,建议查看是否存在大量慢sql并尝试重启进行恢复。
登录运维POD后重启 projex-mysql, 命令如下:
kubectl rollout restart statefulsets projex-mysql -n yunxiao
Projex产品MQ消息1分钟发送成功率低于80%
所属产品: projex
问题分析:查看projex的aone-common-cloud应用cpu和mem使用状况,建议尝试重启。
登录运维POD后重启 aone-common-cloud, 命令如下:
kubectl rollout restart deployment aone-common-cloud -n yunxiao
Testhub测试用例列表成功率低于80%
所属产品: testhub
问题分析:查看testhub相关的应用,aone-workitem-cloud、aone-common-cloud应用以及中间件projex-elasticsearch和projex-mysql的状态,建议尝试重启。
登录运维POD后重启 aone-workitem-cloud, 命令如下:
kubectl rollout restart deployment aone-workitem-cloud -n yunxiao
Testhub测试计划列表成功率低于80%
所属产品: testhub
问题分析:查看testhub相关的应用,aone-workitem-cloud、aone-common-cloud应用以及中间件projex-elasticsearch和projex-mysql的状态,建议尝试重启。
登录运维POD后重启 aone-workitem-cloud, 命令如下:
kubectl rollout restart deployment aone-workitem-cloud -n yunxiao
Testbub产品mysql的CPU使用率超过90%
所属产品: projex
问题分析:查看projex中间件projex-mysql的状态,建议查看是否存在大量慢sql并尝试重启进行恢复。
登录运维POD后重启 projex-mysql, 命令如下:
kubectl rollout restart statefulsets projex-mysql -n yunxiao
Testhub产品搜索引擎CPU使用率超过90%告警
所属产品: projex
问题分析:查看中间件projex-elasticsearch,建议尝试重启进行恢复。
登录运维POD后重启 projex-elasticsearch, 命令如下:
kubectl rollout restart statefulsets projex-elasticsearch -n yunxiao
Docs文档详情展示成功率低于80%
所属产品:文档
问题分析:查看yunxiao-docs应用和docs-mysql的cpu和mem使用情况,建议尝试重启。
登录运维POD后重启 yunxiao-docs, 命令如下:
kubectl rollout restart deployment yunxiao-docs -n yunxiao
Docs文库列表成功率低于80%
所属产品:文档
问题分析:查看yunxiao-docs应用和docs-mysql和docs-elasticsearch的cpu和mem使用情况,建议尝试重启。
登录运维POD后重启 yunxiao-docs, 命令如下:
kubectl rollout restart deployment yunxiao-docs -n yunxiao
Docs产品数据库CPU使用率超过90%
所属产品:文档
问题分析:查看docs-mysql的cpu和mem使用情况,并检查是否存在大量慢sql,建议尝试重启。
登录运维POD后重启 docs-mysql, 命令如下:
kubectl rollout restart statefulsets docs-mysql -n yunxiao
Docs产品搜索引擎CPU使用率超过90%告警
所属产品:文档
问题分析:查看docs-elasticsearch的cpu和mem使用情况,并检查是否存在大量慢sql,建议尝试重启。
登录运维POD后重启 docs-elasticsearch, 命令如下:
kubectl rollout restart statefulsets docs-elasticsearch -n yunxiao
Flow主机部署单成功率 低于90%告警
所属产品:flow
问题分析: 1、分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 aone-armory的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 aone-armory, 命令如下:
kubectl rollout restart deployment aone-armory -n flow
水平扩容 aone-armory 实例到4台的命令如下:
kubectl scale deployment aone-armory --replicas=4 -n flow
2、检查最近的部署单,查看部署日志,如果无日志,就按照文档主机部署场景问题排查部署通道的健康状态,如果有报错日志,按照日志的错误信息排查。
Flow发送MQ成功率低于90%告警
所属产品:flow
问题分析: 1、查看flow命名空间 devops-flow-engine /home/admin/logs/ons.log ,查看具体报错原因; 2、检查yunxiao命名空间下rocketmq-broker服务是否正常,可以重启服务。 登录运维POD后重启 rocketmq, 命令如下:
kubectl -n yunxiao rollout restart deployment rocketmq-broker
kubectl -n yunxiao rollout restart statefulsets rocketmq-namesrv
Flow定时任务、代码触发、webhook 运行流水线成功率 低于90%告警
所属产品:flow
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 devops-flow-engine 和 aone-execution-component的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 devops-flow-engine和aone-execution-component, 命令如下:
kubectl rollout restart deployment devops-flow-engine -n flow
kubectl rollout restart deployment aone-execution-component -n flow
水平扩容 devops-flow-engine 实例到4台的命令如下:
kubectl scale deployment devops-flow-engine --replicas=4 -n flow
水平扩容 aone-execution-component 实例到4台的命令如下:
kubectl scale deployment aone-execution-component --replicas=4 -n flow
Flow构建机申请环境成功率低于90%告警
所属产品:flow
问题分析:1、检查构建集群中的机器状态;2、检查构建集群中的机器的Runner状态,按照runner 排查工具Runner 常用操作进行排查处理;
Flow获取步骤运行参数接口成功率低于90%告警
所属产品:flow
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 aone-execution-component的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 aone-execution-component, 命令如下:
kubectl rollout restart deployment aone-execution-component -n flow
水平扩容 aone-execution-component 实例到4台的命令如下:
kubectl scale deployment aone-execution-component --replicas=4 -n flow
Flow获取流水线列表成功率低于90%告警
所属产品:flow
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 devops-flow-engine 和 rdc-tb-web的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 devops-flow-engine和rdc-tb-web, 命令如下:
kubectl rollout restart deployment devops-flow-engine -n flow
kubectl rollout restart deployment rdc-tb-web -n flow
水平扩容 devops-flow-engine 实例到4台的命令如下:
kubectl scale deployment devops-flow-engine --replicas=4 -n flow
水平扩容 rdc-tb-web 实例到4台的命令如下:
kubectl scale deployment rdc-tb-web --replicas=4 -n flow
Flow页面+API触发流水线成功率低于90%告警
所属产品:flow
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 devops-flow-engine 和 aone-execution-component的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 devops-flow-engine和aone-execution-component, 命令如下:
kubectl rollout restart deployment devops-flow-engine -n flow
kubectl rollout restart deployment aone-execution-component -n flow
水平扩容 devops-flow-engine 实例到4台的命令如下:
kubectl scale deployment devops-flow-engine --replicas=4 -n flow
水平扩容 aone-execution-component 实例到4台的命令如下:
kubectl scale deployment aone-execution-component --replicas=4 -n flow
Flow构建等待运行任务数大于10告警
所属产品:flow
问题分析:1、检查构建集群中的机器状态;2、检查构建集群中的机器的Runner状态,按照runner 排查工具Runner 常用操作进行排查处理;
Flow触发构建接口成功率低于90%告警
所属产品:flow
问题分析:分析接口的状态码,如果接口有明显500报错,检查报错日志,进一步确定恢复方法;检查应用 aone-execution-component 和 aone-build-engine-cloud的CPU、Memory过高,如短期过高,尝试重启;检查磁盘空间的饱和度,确认是否需要扩容。 登录运维POD后重启 aone-execution-component和aone-build-engine-cloud, 命令如下:
kubectl rollout restart deployment aone-execution-component -n flow
kubectl rollout restart deployment aone-build-engine-cloud -n flow
水平扩容 daone-execution-component 实例到4台的命令如下:
kubectl scale deployment aone-execution-component --replicas=4 -n flow
水平扩容 aone-build-engine-cloud 实例到4台的命令如下:
kubectl scale deployment aone-build-engine-cloud --replicas=4 -n flow
通用运维操作
登录运维POD
在yunxiao命名空间有个名为init-admin-0的POD,这是云效的运维容器,有着诸多运维工具和脚本。访问POD的方式有两种,介绍如下:
通过云效K8S 控制台访问方式:在登录上控制台之后,命名空间切换到yunxiao,选择Pod视图,可以通过查询或者翻页找到init-admin-0的Pod,点击右侧的更多图标,选择“执行”,即可登录
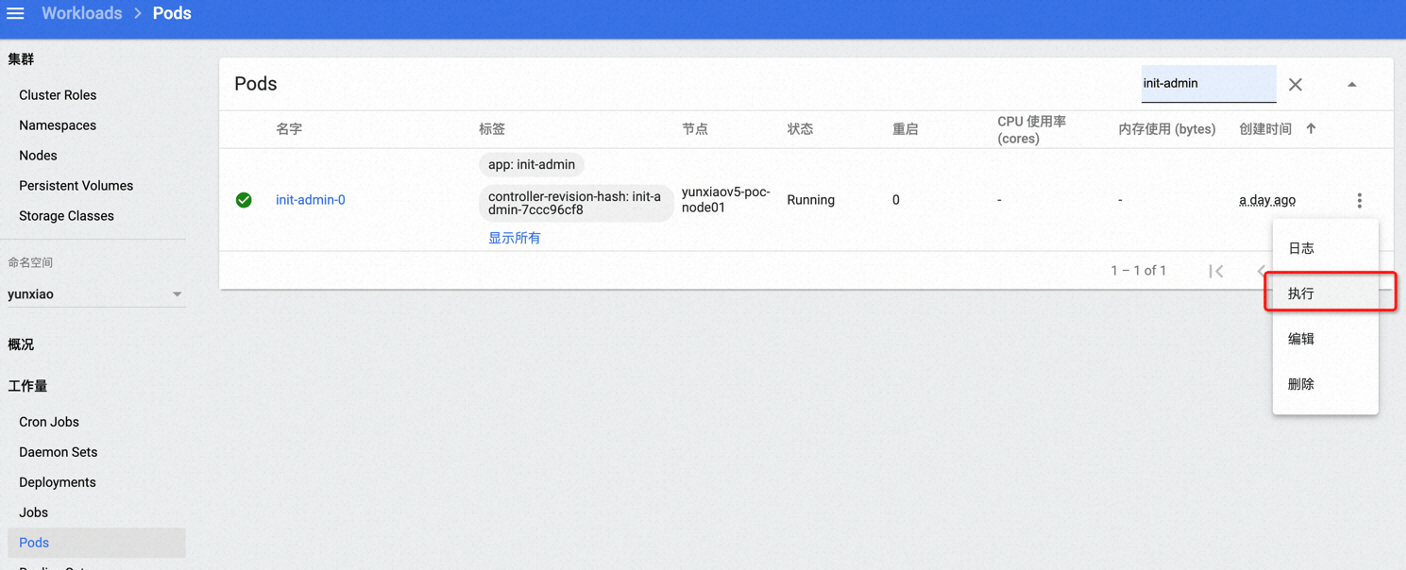
可以在能够执行kubectl 访问云效K8S集群的命令行窗口执行:
kubectl -n yunxiao exec -it init-admin-0 -- bash
重启应用
有两种办法,任选其一即可
- 登录K8S Dashboard控制台,在左侧导航栏中选择Pod页面,注意namespace也要选择。然后可以在右侧页面查找并选择应用的POD,通过最右侧的操作栏-“删除”,可以将指定的POD删除,由于K8S的机器,POD会自动重启
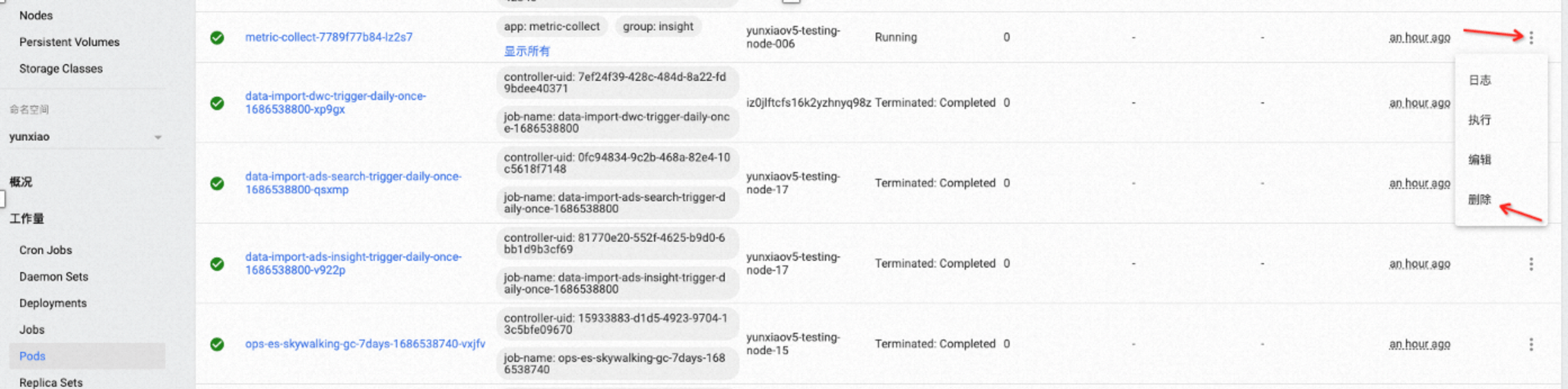
- 在运维POD(init-admin-0)中用kubectl 操作重启
示例重启命令:
kubectl rollout restart deployment metric-collect -n yunxiao
水平扩缩容应用
有两种办法,任选其一即可,注意此方法操作扩容操作只是临时解决,不会持久化,下次升级后会失效,需要把此扩容操作内容记录下来,反馈给云效技术支持同学
- 登录K8S Dashboard控制台,在左侧导航栏中选择Deployment页面,注意namespace也要选择。然后可以在右侧页面查找并选择应用,通过最右侧的操作栏-“规模”,可以通过调整副本数的数量进行水平扩容或者缩容
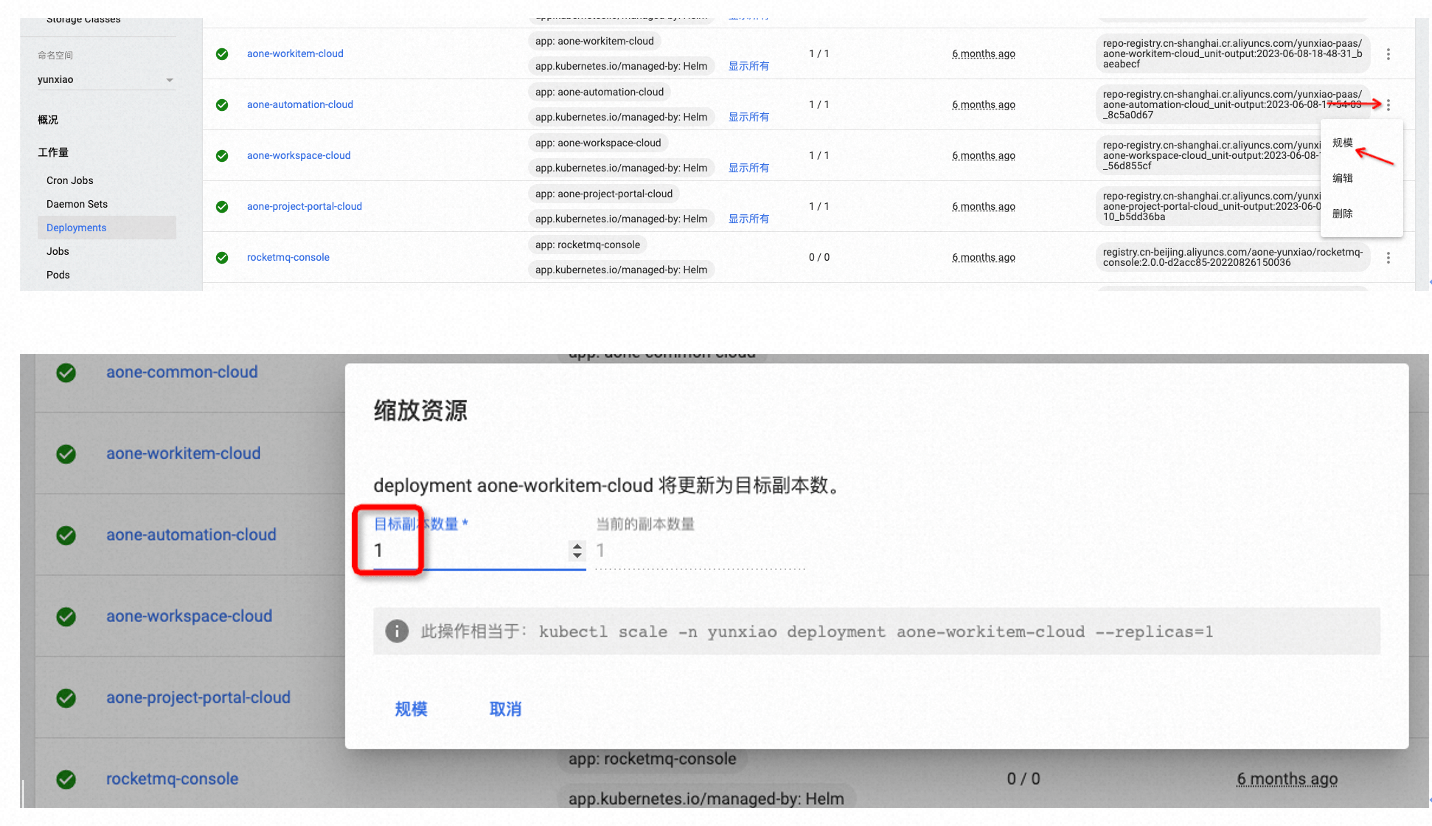
- 在运维POD(init-admin-0)中用 kubectl 操作水平扩容
示例水平扩容命令:
kubectl scale deployment metric-collect --replicas=4 -n yunxiao
垂直扩容应用
有两种办法,任选其一即可,注意此方法操作扩容操作只是临时解决,不会持久化,下次升级后会失效,需要把此扩容操作内容记录下来,反馈给云效技术支持同学。
- 登录K8S Dashboard控制台,在左侧导航栏中选择Deployment页面,注意namespace也要选择。然后可以在右侧页面查找并选择应用,通过最右侧的操作栏-“编辑”,可以编辑Deployment的内容。在编辑页面中,通过调整resources的cpu和memory内存大小,来实现应用的垂直扩容
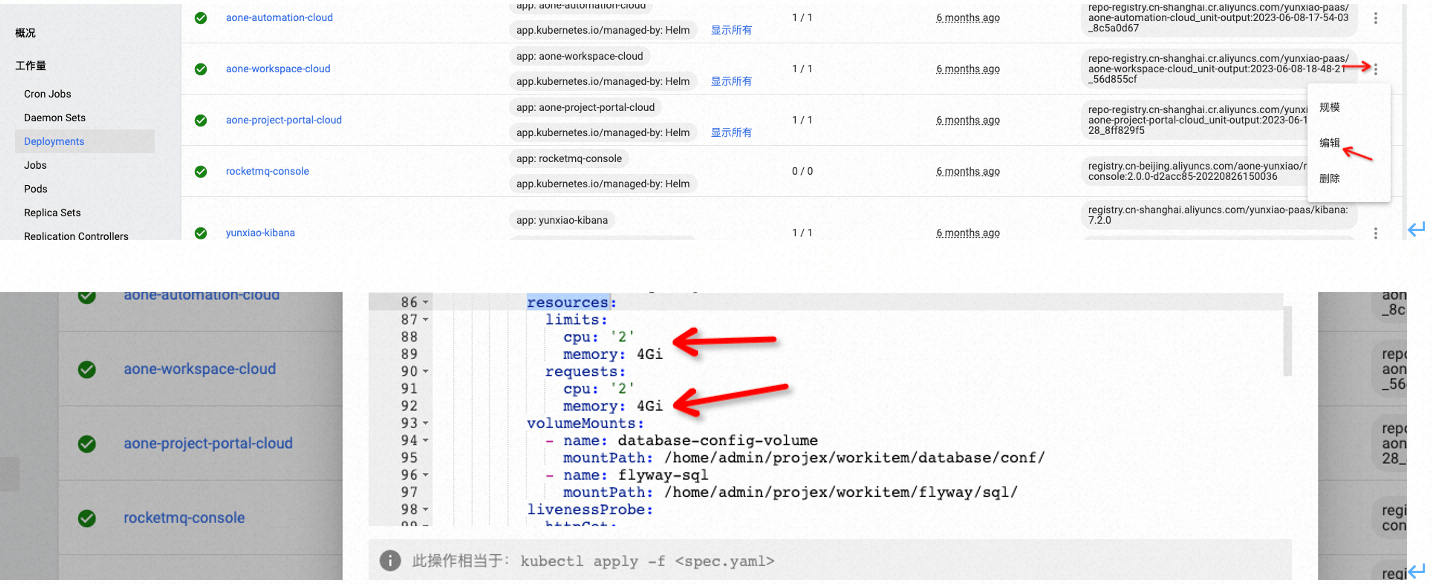
- 在运维POD(init-admin-0)中用kubectl 操作垂直扩容
示例垂直扩容命令:
# kubectl get deployment <deployment-name> -o yaml > deployment.yaml
kubectl get deployment metric-collect -n yunxiao -o yaml > deployment.yaml
# vim修改加大 resources.limits.memory 和 resources.requests.memory 字段值
kubectl apply -f deployment.yaml -n yunxiao
# 查看修改是否生效
kubectl get deployment metric-collect -n yunxiao -o yaml